* 내가 읽으려고 내 맘대로 번역한 글.
* 원문 : https://docs.swift.org/swift-book/LanguageGuide/StringsAndCharacters.html
Strings and Characters
A string is a series of characters, such as "hello, world" or "albatross". Swift strings are represented by the String type. The contents of a String can be accessed in various ways, including as a collection of Character values.
Swift’s String and Character types provide a fast, Unicode-compliant way to work with text in your code. The syntax for string creation and manipulation is lightweight and readable, with a string literal syntax that is similar to C. String concatenation is as simple as combining two strings with the + operator, and string mutability is managed by choosing between a constant or a variable, just like any other value in Swift. You can also use strings to insert constants, variables, literals, and expressions into longer strings, in a process known as string interpolation. This makes it easy to create custom string values for display, storage, and printing.
Despite this simplicity of syntax, Swift’s String type is a fast, modern string implementation. Every string is composed of encoding-independent Unicode characters, and provides support for accessing those characters in various Unicode representations.
스킵...
NOTE
Swift’s String type is bridged with Foundation’s NSString class. Foundation also extends String to expose methods defined by NSString. This means, if you import Foundation, you can access those NSString methods on String without casting.
For more information about using String with Foundation and Cocoa, see Bridging Between String and NSString.
swift의 String타입은 Foundation의 NSString 클래스와 연결된다.
Foundation은 NSString에서 정의된 메소드들을 제공하기 위해 String을 확장한다.
그래서 Foundation을 import 하면 String에서 NSString 메소드를 바로 사용할수 있다.
String Literals
You can include predefined String values within your code as string literals. A string literal is a sequence of characters surrounded by double quotation marks (").
Use a string literal as an initial value for a constant or variable:
- let someString = "Some string literal value"
Note that Swift infers a type of String for the someString constant because it’s initialized with a string literal value.
Multiline String Literals
If you need a string that spans several lines, use a multiline string literal—a sequence of characters surrounded by three double quotation marks:
여러줄에 걸친 문자열은 쌍따옴표 3개로 묶어라 (""")
- let quotation = """
- The White Rabbit put on his spectacles. "Where shall I begin,
- please your Majesty?" he asked.
- "Begin at the beginning," the King said gravely, "and go on
- till you come to the end; then stop."
- """
A multiline string literal includes all of the lines between its opening and closing quotation marks. The string begins on the first line after the opening quotation marks (""") and ends on the line before the closing quotation marks, which means that neither of the strings below start or end with a line break:
- let singleLineString = "These are the same."
- let multilineString = """
- These are the same.
- """
When your source code includes a line break inside of a multiline string literal, that line break also appears in the string’s value. If you want to use line breaks to make your source code easier to read, but you don’t want the line breaks to be part of the string’s value, write a backslash (\) at the end of those lines:
- let softWrappedQuotation = """
- The White Rabbit put on his spectacles. "Where shall I begin, \
- please your Majesty?" he asked.
- "Begin at the beginning," the King said gravely, "and go on \
- till you come to the end; then stop."
- """
To make a multiline string literal that begins or ends with a line feed, write a blank line as the first or last line. For example:
- let lineBreaks = """
- This string starts with a line break.
- It also ends with a line break.
- """
A multiline string can be indented to match the surrounding code. The whitespace before the closing quotation marks (""") tells Swift what whitespace to ignore before all of the other lines. However, if you write whitespace at the beginning of a line in addition to what’s before the closing quotation marks, that whitespace is included.
다중행 문자열은 들여쓰기가 가능하다.
닫는기호(""") 앞에 있는 스페이스 갯수만큼, 각 행의 문자열 앞의 스페이스는 무시되고, 나머지는 스페이스만큼 들여쓰기 된다.
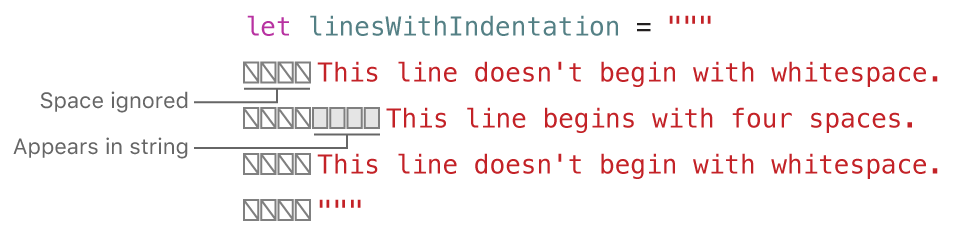
In the example above, even though the entire multiline string literal is indented, the first and last lines in the string don’t begin with any whitespace. The middle line has more indentation than the closing quotation marks, so it starts with that extra four-space indentation.
위의 예에서 맨 끝에 있는 닫는기호 (""") 앞에 스페이스가 4칸 있으니까,
1번째, 2번째 라인에서 앞에 있는 스페이스 4칸은 무시된다.
그래서 1번째, 3번째 라인은 들여쓰기가 안되고, 2번째 라인은 스페이스 4칸만큼 들여쓰기 된다.
(이상한 방식이군...)
Special Characters in String Literals
String literals can include the following special characters:
문자열은 다음과 같은 특수기호를 포함할수 있다.
- The escaped special characters \0 (null character), \\ (backslash), \t (horizontal tab), \n (line feed), \r (carriage return), \" (double quotation mark) and \' (single quotation mark)
- An arbitrary Unicode scalar value, written as \u{n}, where n is a 1–8 digit hexadecimal number (Unicode is discussed in Unicode below)
The code below shows four examples of these special characters. The wiseWords constant contains two escaped double quotation marks. The dollarSign, blackHeart, and sparklingHeart constants demonstrate the Unicode scalar format:
- let wiseWords = "\"Imagination is more important than knowledge\" - Einstein"
- // "Imagination is more important than knowledge" - Einstein
- let dollarSign = "\u{24}" // $, Unicode scalar U+0024
- let blackHeart = "\u{2665}" // ♥, Unicode scalar U+2665
- let sparklingHeart = "\u{1F496}" // 💖, Unicode scalar U+1F496
Because multiline string literals use three double quotation marks instead of just one, you can include a double quotation mark (") inside of a multiline string literal without escaping it. To include the text """ in a multiline string, escape at least one of the quotation marks. For example:
- let threeDoubleQuotationMarks = """
- Escaping the first quotation mark \"""
- Escaping all three quotation marks \"\"\"
- """
Extended String Delimiters
You can place a string literal within extended delimiters to include special characters in a string without invoking their effect. You place your string within quotation marks (") and surround that with number signs (#). For example, printing the string literal #"Line 1\nLine 2"# prints the line feed escape sequence (\n) rather than printing the string across two lines.
If you need the special effects of a character in a string literal, match the number of number signs within the string following the escape character (\). For example, if your string is #"Line 1\nLine 2"# and you want to break the line, you can use #"Line 1\#nLine 2"#instead. Similarly, ###"Line1\###nLine2"### also breaks the line.
String literals created using extended delimiters can also be multiline string literals. You can use extended delimiters to include the text """ in a multiline string, overriding the default behavior that ends the literal. For example:
- let threeMoreDoubleQuotationMarks = #"""
- Here are three more double quotes: """
- """#
Initializing an Empty String
To create an empty String value as the starting point for building a longer string, either assign an empty string literal to a variable, or initialize a new String instance with initializer syntax:
- var emptyString = "" // empty string literal
- var anotherEmptyString = String() // initializer syntax
- // these two strings are both empty, and are equivalent to each other
Find out whether a String value is empty by checking its Boolean isEmpty property:
- if emptyString.isEmpty {
- print("Nothing to see here")
- }
- // Prints "Nothing to see here"
String Mutability
You indicate whether a particular String can be modified (or mutated) by assigning it to a variable (in which case it can be modified), or to a constant (in which case it can’t be modified):
- var variableString = "Horse"
- variableString += " and carriage"
- // variableString is now "Horse and carriage"
- let constantString = "Highlander"
- constantString += " and another Highlander"
- // this reports a compile-time error - a constant string cannot be modified
NOTE
This approach is different from string mutation in Objective-C and Cocoa, where you choose between two classes (NSString and NSMutableString) to indicate whether a string can be mutated.
Strings Are Value Types
Swift’s String type is a value type. If you create a new String value, that String value is copied when it’s passed to a function or method, or when it’s assigned to a constant or variable. In each case, a new copy of the existing String value is created, and the new copy is passed or assigned, not the original version. Value types are described in Structures and Enumerations Are Value Types.
swift에서 String은 값타입이다.
함수 또는 메소드에 넘기거나, 다른 상수 또는 변수에 할당할때 값이 복사된다.
새로운 값의 복사본이 생성되고, 그 새로운 값이 사용된다. 원래 값이 사용되지 않는다.
Swift’s copy-by-default String behavior ensures that when a function or method passes you a String value, it’s clear that you own that exact String value, regardless of where it came from. You can be confident that the string you are passed won’t be modified unless you modify it yourself.
Behind the scenes, Swift’s compiler optimizes string usage so that actual copying takes place only when absolutely necessary. This means you always get great performance when working with strings as value types.
String은 call by value 다.
swift 컴파일러가 최적화 해서 실제로 문자열이 사용될때 복사를 수행한다. 그래서 성능이 좋다.
Working with Characters
You can access the individual Character values for a String by iterating over the string with a for-in loop:
- for character in "Dog!🐶" {
- print(character)
- }
- // D
- // o
- // g
- // !
- // 🐶
The for-in loop is described in For-In Loops.
Alternatively, you can create a stand-alone Character constant or variable from a single-character string literal by providing a Character type annotation:
- let exclamationMark: Character = "!"
String values can be constructed by passing an array of Character values as an argument to its initializer:
- let catCharacters: [Character] = ["C", "a", "t", "!", "🐱"]
- let catString = String(catCharacters)
- print(catString)
- // Prints "Cat!🐱"
Concatenating Strings and Characters
String values can be added together (or concatenated) with the addition operator (+) to create a new String value:
- let string1 = "hello"
- let string2 = " there"
- var welcome = string1 + string2
- // welcome now equals "hello there"
You can also append a String value to an existing String variable with the addition assignment operator (+=):
- var instruction = "look over"
- instruction += string2
- // instruction now equals "look over there"
You can append a Character value to a String variable with the String type’s append()method:
- let exclamationMark: Character = "!"
- welcome.append(exclamationMark)
- // welcome now equals "hello there!"
NOTE
You can’t append a String or Character to an existing Character variable, because a Character value must contain a single character only.
Character 타입은 문자 1개만 가질수 있다.
If you’re using multiline string literals to build up the lines of a longer string, you want every line in the string to end with a line break, including the last line. For example:
let badStart = """
one
two
"""
let end = """
three
"""
print(badStart + end)
// Prints two lines:
// one
// twothree
let goodStart = """
one
two
"""
print(goodStart + end)
// Prints three lines:
// one
// two
// three
In the code above, concatenating badStart with end produces a two-line string, which isn’t the desired result. Because the last line of badStart doesn’t end with a line break, that line gets combined with the first line of end. In contrast, both lines of goodStart end with a line break, so when it’s combined with end the result has three lines, as expected.
String Interpolation
String interpolation is a way to construct a new String value from a mix of constants, variables, literals, and expressions by including their values inside a string literal. You can use string interpolation in both single-line and multiline string literals. Each item that you insert into the string literal is wrapped in a pair of parentheses, prefixed by a backslash (\):
- let multiplier = 3
- let message = "\(multiplier) times 2.5 is \(Double(multiplier) * 2.5)"
- // message is "3 times 2.5 is 7.5"
In the example above, the value of multiplier is inserted into a string literal as \(multiplier). This placeholder is replaced with the actual value of multiplier when the string interpolation is evaluated to create an actual string.
위의 예에서, multiplier 변수의 값이 문자열의 \(multiplier) 자리에 들어간다.
The value of multiplier is also part of a larger expression later in the string. This expression calculates the value of Double(multiplier) * 2.5 and inserts the result (7.5) into the string. In this case, the expression is written as \(Double(multiplier) * 2.5) when it’s included inside the string literal.
You can use extended string delimiters to create strings containing characters that would otherwise be treated as a string interpolation. For example:
- print(#"Write an interpolated string in Swift using \(multiplier)."#)
- // Prints "Write an interpolated string in Swift using \(multiplier)."
To use string interpolation inside a string that uses extended delimiters, match the number of number signs before the backslash to the number of number signs at the beginning and end of the string. For example:
- print(#"6 times 7 is \#(6 * 7)."#)
- // Prints "6 times 7 is 42."
NOTE
The expressions you write inside parentheses within an interpolated string can’t contain an unescaped backslash (\), a carriage return, or a line feed. However, they can contain other string literals.
Unicode
Unicode is an international standard for encoding, representing, and processing text in different writing systems. It enables you to represent almost any character from any language in a standardized form, and to read and write those characters to and from an external source such as a text file or web page. Swift’s String and Character types are fully Unicode-compliant, as described in this section.
Unicode Scalar Values
Behind the scenes, Swift’s native String type is built from Unicode scalar values. A Unicode scalar value is a unique 21-bit number for a character or modifier, such as U+0061 for LATIN SMALL LETTER A ("a"), or U+1F425 for FRONT-FACING BABY CHICK ("🐥").
Note that not all 21-bit Unicode scalar values are assigned to a character—some scalars are reserved for future assignment or for use in UTF-16 encoding. Scalar values that have been assigned to a character typically also have a name, such as LATIN SMALL LETTER A and FRONT-FACING BABY CHICK in the examples above.
Extended Grapheme Clusters
Every instance of Swift’s Character type represents a single extended grapheme cluster. An extended grapheme cluster is a sequence of one or more Unicode scalars that (when combined) produce a single human-readable character.
Here’s an example. The letter é can be represented as the single Unicode scalar é(LATIN SMALL LETTER E WITH ACUTE, or U+00E9). However, the same letter can also be represented as a pair of scalars—a standard letter e (LATIN SMALL LETTER E, or U+0065), followed by the COMBINING ACUTE ACCENT scalar (U+0301). The COMBINING ACUTE ACCENTscalar is graphically applied to the scalar that precedes it, turning an e into an é when it’s rendered by a Unicode-aware text-rendering system.
In both cases, the letter é is represented as a single Swift Character value that represents an extended grapheme cluster. In the first case, the cluster contains a single scalar; in the second case, it’s a cluster of two scalars:
- let eAcute: Character = "\u{E9}" // é
- let combinedEAcute: Character = "\u{65}\u{301}" // e followed by ́
- // eAcute is é, combinedEAcute is é
Extended grapheme clusters are a flexible way to represent many complex script characters as a single Character value. For example, Hangul syllables from the Korean alphabet can be represented as either a precomposed or decomposed sequence. Both of these representations qualify as a single Character value in Swift:
- let precomposed: Character = "\u{D55C}" // 한
- let decomposed: Character = "\u{1112}\u{1161}\u{11AB}" // ᄒ, ᅡ, ᆫ
- // precomposed is 한, decomposed is 한
Extended grapheme clusters enable scalars for enclosing marks (such as COMBINING ENCLOSING CIRCLE, or U+20DD) to enclose other Unicode scalars as part of a single Character value:
- let enclosedEAcute: Character = "\u{E9}\u{20DD}"
- // enclosedEAcute is é⃝
Unicode scalars for regional indicator symbols can be combined in pairs to make a single Character value, such as this combination of REGIONAL INDICATOR SYMBOL LETTER U(U+1F1FA) and REGIONAL INDICATOR SYMBOL LETTER S (U+1F1F8):
- let regionalIndicatorForUS: Character = "\u{1F1FA}\u{1F1F8}"
- // regionalIndicatorForUS is 🇺🇸
Counting Characters
To retrieve a count of the Character values in a string, use the count property of the string:
- let unusualMenagerie = "Koala 🐨, Snail 🐌, Penguin 🐧, Dromedary 🐪"
- print("unusualMenagerie has \(unusualMenagerie.count) characters")
- // Prints "unusualMenagerie has 40 characters"
Note that Swift’s use of extended grapheme clusters for Character values means that string concatenation and modification may not always affect a string’s character count.
For example, if you initialize a new string with the four-character word cafe, and then append a COMBINING ACUTE ACCENT (U+0301) to the end of the string, the resulting string will still have a character count of 4, with a fourth character of é, not e:
- var word = "cafe"
- print("the number of characters in \(word) is \(word.count)")
- // Prints "the number of characters in cafe is 4"
- word += "\u{301}" // COMBINING ACUTE ACCENT, U+0301
- print("the number of characters in \(word) is \(word.count)")
- // Prints "the number of characters in café is 4"
NOTE
Extended grapheme clusters can be composed of multiple Unicode scalars. This means that different characters—and different representations of the same character—can require different amounts of memory to store. Because of this, characters in Swift don’t each take up the same amount of memory within a string’s representation. As a result, the number of characters in a string can’t be calculated without iterating through the string to determine its extended grapheme cluster boundaries. If you are working with particularly long string values, be aware that the countproperty must iterate over the Unicode scalars in the entire string in order to determine the characters for that string.
The count of the characters returned by the count property isn’t always the same as the lengthproperty of an NSString that contains the same characters. The length of an NSString is based on the number of 16-bit code units within the string’s UTF-16 representation and not the number of Unicode extended grapheme clusters within the string.
Accessing and Modifying a String
You access and modify a string through its methods and properties, or by using subscript syntax.
String Indices
Each String value has an associated index type, String.Index, which corresponds to the position of each Character in the string.
As mentioned above, different characters can require different amounts of memory to store, so in order to determine which Character is at a particular position, you must iterate over each Unicode scalar from the start or end of that String. For this reason, Swift strings can’t be indexed by integer values.
문자열에서 각 문자의 위치는 String.Index에 연관되어 있다.
위에서 언급했듯이, 글자들은 각각 다른 메모리 양을 필요로 하기 때문에, 어떤 글자가 어느 위치에 있는지 알아내려면
문자열의 처음글자부터 끝글자까지 루프돌면서 확인해야 한다.
swift의 문자열은 정수값 index 로 바로 해당 글자를 바로 알수 없다.
이석우 추가 : 문자열[3] -> 이런식으로 정수값 index를 못 사용한다는 뜻. 이거 좀 불편하겠다.
Use the startIndex property to access the position of the first Character of a String. The endIndex property is the position after the last character in a String. As a result, the endIndex property isn’t a valid argument to a string’s subscript. If a String is empty, startIndex and endIndex are equal.
startIndex : 처음글자의 위치
endIndex : 마지막글자의 위치 + 1
따라서 endIndex는 문자열의 첨자를 벗어난다.
문자열이 비어 있으면 startIndex와 endIndex는 동일하다.
You access the indices before and after a given index using the index(before:) and index(after:) methods of String. To access an index farther away from the given index, you can use the index(_:offsetBy:) method instead of calling one of these methods multiple times.
index(before:) : 주어진 index의 앞 index를 구함
index(after:) : 주어진 index의 뒤 index를 구함
index(_:offsetBy:) : 주어진 index에서 offsetBy 만큼 떨어진 index를 구함
You can use subscript syntax to access the Character at a particular String index.
- let greeting = "Guten Tag!"
- greeting[greeting.startIndex]
- // G
- greeting[greeting.index(before: greeting.endIndex)]
- // !
- greeting[greeting.index(after: greeting.startIndex)]
- // u
- let index = greeting.index(greeting.startIndex, offsetBy: 7)
- greeting[index]
- // a
Attempting to access an index outside of a string’s range or a Character at an index outside of a string’s range will trigger a runtime error.
문자열 범위를 넘어가는 index는 런타임 에러남.
- greeting[greeting.endIndex] // Error
- greeting.index(after: greeting.endIndex) // Error
Use the indices property to access all of the indices of individual characters in a string.
for index in greeting.indices {
print("\(greeting[index]) ", terminator: "")
}
// Prints "G u t e n T a g ! "
NOTE
You can use the startIndex and endIndex properties and the index(before:), index(after:), and index(_:offsetBy:) methods on any type that conforms to the Collection protocol. This includes String, as shown here, as well as collection types such as Array, Dictionary, and Set.
startIndex, endIndex, index(before:), index(after:), index(_:offsetBy:) 등은 문자열뿐만 아니라
Collection protocol을 구현하는 모든 타입에 사용가능하다.
Array, Dictionary, Set 등.
Inserting and Removing
To insert a single character into a string at a specified index, use the insert(_:at:)method, and to insert the contents of another string at a specified index, use the insert(contentsOf:at:) method.
문자열의 특정위치에 한글자를 추가하려면 insert(_:at:) 메소드를 사용해라.
문자열의 특정위치에 문자열을 추가하려면 insert(contentsOf:at:) 메소드를 사용해라.
var welcome = "hello"
welcome.insert("!", at: welcome.endIndex)
// welcome now equals "hello!"
welcome.insert(contentsOf: " there", at: welcome.index(before: welcome.endIndex))
// welcome now equals "hello there!"
To remove a single character from a string at a specified index, use the remove(at:)method, and to remove a substring at a specified range, use the removeSubrange(_:)method:
문자열에서 특정위치의 한글자를 제거하려면 remove(at:)
문자열에서 특정범위의 문자열을 제거하려면 removeSubrange(_:)
welcome.remove(at: welcome.index(before: welcome.endIndex))
// welcome now equals "hello there"
let range = welcome.index(welcome.endIndex, offsetBy: -6)..<welcome.endIndex
welcome.removeSubrange(range)
// welcome now equals "hello"
NOTE
You can use the insert(_:at:), insert(contentsOf:at:), remove(at:), and removeSubrange(_:) methods on any type that conforms to the RangeReplaceableCollectionprotocol. This includes String, as shown here, as well as collection types such as Array, Dictionary, and Set.
insert(_:at:), insert(contentsOf:at:), remove(at:), removeSubrange(_:) 메소드는
RangeReplaceableCollection protocol 을 구현한 모든 타입에 사용가능하다.
Array, Dictionary, Set 등
Substrings
When you get a substring from a string—for example, using a subscript or a method like prefix(_:)—the result is an instance of Substring, not another string. Substrings in Swift have most of the same methods as strings, which means you can work with substrings the same way you work with strings. However, unlike strings, you use substrings for only a short amount of time while performing actions on a string. When you’re ready to store the result for a longer time, you convert the substring to an instance of String. For example:
문자열에서 일부분을 얻으면 그 결과는 String 타입이 아니고 Substring 타입이다.
(예를 들어 문자열[index] 또는 prefix(_:) 같은 메소드를 사용했을때)
Substring 타입은 문자열과 거의 동일한 메소드들을 가지고 있어서, 문자열을 다루듯이 Substring을 다룰수 있다.
그렇지만 문자열과는 다르게 substring은 문자열을 다룰때 임시변수로만 사용해라.
오랫동안 저장할때는 String타입으로 변환해라. -> 왜 일까? 아래에 설명이 있음.
let greeting = "Hello, world!"
let index = greeting.firstIndex(of: ",") ?? greeting.endIndex
let beginning = greeting[..<index]
// beginning is "Hello"
// Convert the result to a String for long-term storage.
let newString = String(beginning)
Like strings, each substring has a region of memory where the characters that make up the substring are stored. The difference between strings and substrings is that, as a performance optimization, a substring can reuse part of the memory that’s used to store the original string, or part of the memory that’s used to store another substring. (Strings have a similar optimization, but if two strings share memory, they are equal.) This performance optimization means you don’t have to pay the performance cost of copying memory until you modify either the string or substring. As mentioned above, substrings aren’t suitable for long-term storage—because they reuse the storage of the original string, the entire original string must be kept in memory as long as any of its substrings are being used.
문자열처럼, 각 substring은 문자들을 저장할 메모리영역을 가지고 있다.
성능최적화 관점에서 문자열과 substring의 차이점은,
원래 문자열이나 다른 substring이 저장되어 있는 메모리의 일부를 substring이 재사용한다는 것이다.
(문자열도 비슷한 최적화를 가지고 있지만, 2개의 문자열이 메모리를 공유한다면, 그 둘은 같은것이다)
이 성능최적하는 너가 원래 문자열이나 substring을 수정하기 전까지 메모리를 복사하는 작업이 필요없다는걸 뜻한다.
위에서 언급했듯이, substring은 장기간 보관에 알맞지 않다.
왜냐면 원래 문자열의 저장소를 재사용하기 때문에 substring이 사용완료 될때까지 원래 문자열 전체를 메모리에 상주시켜야 하니까.
이석우 추가 : 대충 조금 알팍하게 알겠고... 요점은 substring은 임시변수로만 써라.
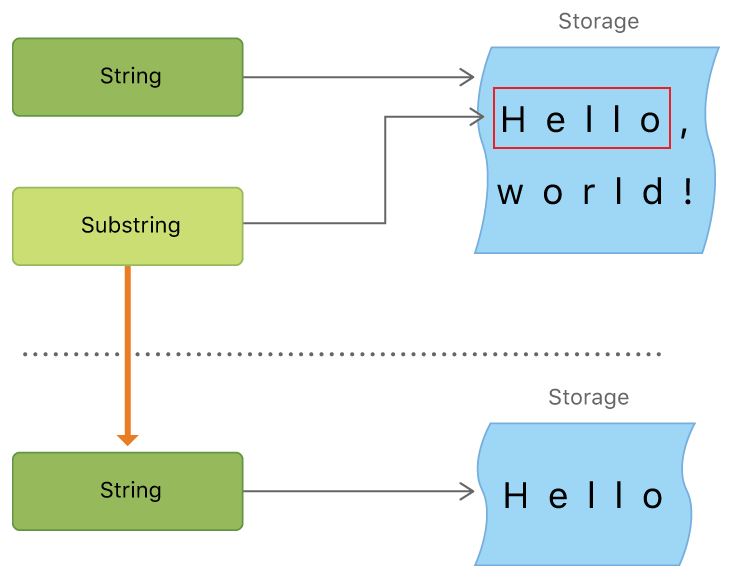
In the example above, greeting is a string, which means it has a region of memory where the characters that make up the string are stored. Because beginning is a substring of greeting, it reuses the memory that greeting uses. In contrast, newString is a string—when it’s created from the substring, it has its own storage. The figure below shows these relationships:
위의 예에서, greeting은 문자열이다. 이것은 문자열을 이루는 문자들이 저장될 메모리 영역을 가지고 있다는 뜻이다.
begining은 greeting의 substring이기 때문에, greeting이 사용하는 메모리를 같이 사용한다.
반면 newString은 substring에서 만들어진 문자열이라서, 자신의 메모리 공간을 가지고 있다.
NOTE
Both String and Substring conform to the StringProtocol protocol, which means it’s often convenient for string-manipulation functions to accept a StringProtocol value. You can call such functions with either a String or Substring value.
String타입과 Substring타입 둘다 StringProtocol을 구현하였다.
그래서 너가 문자열을 다루는 함수를 만든다면 StringProtocol값을 매개변수로 받는게 편하다.
그러면 그 함수는 String 또는 Substring 값을 둘다 넣어서 호출할수 있다.
Comparing Strings
Swift provides three ways to compare textual values: string and character equality, prefix equality, and suffix equality.
문자열이 같은지, 접미사가 같은지, 접두사가 같은지 비교하는 3가지 방법이 있다.
String and Character Equality
String and character equality is checked with the “equal to” operator (==) and the “not equal to” operator (!=), as described in Comparison Operators:
문자열과 문자가 같은지 비교하려면 ==
다른지 비교하려면 !=
let quotation = "We're a lot alike, you and I."
let sameQuotation = "We're a lot alike, you and I."
if quotation == sameQuotation {
print("These two strings are considered equal")
}
// Prints "These two strings are considered equal"
Two String values (or two Character values) are considered equal if their extended grapheme clusters are canonically equivalent. Extended grapheme clusters are canonically equivalent if they have the same linguistic meaning and appearance, even if they’re composed from different Unicode scalars behind the scenes.
For example, LATIN SMALL LETTER E WITH ACUTE (U+00E9) is canonically equivalent to LATIN SMALL LETTER E (U+0065) followed by COMBINING ACUTE ACCENT (U+0301). Both of these extended grapheme clusters are valid ways to represent the character é, and so they’re considered to be canonically equivalent:
무슨 뜻인지 모르겠으므로... 패스...
- // "Voulez-vous un café?" using LATIN SMALL LETTER E WITH ACUTE
- let eAcuteQuestion = "Voulez-vous un caf\u{E9}?"
- // "Voulez-vous un café?" using LATIN SMALL LETTER E and COMBINING ACUTE ACCENT
- let combinedEAcuteQuestion = "Voulez-vous un caf\u{65}\u{301}?"
- if eAcuteQuestion == combinedEAcuteQuestion {
- print("These two strings are considered equal")
- }
- // Prints "These two strings are considered equal"
Conversely, LATIN CAPITAL LETTER A (U+0041, or "A"), as used in English, is not equivalent to CYRILLIC CAPITAL LETTER A (U+0410, or "А"), as used in Russian. The characters are visually similar, but don’t have the same linguistic meaning:
- let latinCapitalLetterA: Character = "\u{41}"
- let cyrillicCapitalLetterA: Character = "\u{0410}"
- if latinCapitalLetterA != cyrillicCapitalLetterA {
- print("These two characters are not equivalent.")
- }
- // Prints "These two characters are not equivalent."
NOTE
String and character comparisons in Swift are not locale-sensitive.
Prefix and Suffix Equality
To check whether a string has a particular string prefix or suffix, call the string’s hasPrefix(_:) and hasSuffix(_:) methods, both of which take a single argument of type String and return a Boolean value.
The examples below consider an array of strings representing the scene locations from the first two acts of Shakespeare’s Romeo and Juliet:
문자열에서 특정 접두사 또는 접미사가 있는지 확인하려면 hasPrefix(_:) hasSuffix(_:) 를 써라.
둘다 문자열 하나를 매개변수로 받고, Boolean 값을 리턴한다.
아래 예는 세익스피어의 로미오와줄리엣의 처음 2장면을 표현한다.
let romeoAndJuliet = [
"Act 1 Scene 1: Verona, A public place",
"Act 1 Scene 2: Capulet's mansion",
"Act 1 Scene 3: A room in Capulet's mansion",
"Act 1 Scene 4: A street outside Capulet's mansion",
"Act 1 Scene 5: The Great Hall in Capulet's mansion",
"Act 2 Scene 1: Outside Capulet's mansion",
"Act 2 Scene 2: Capulet's orchard",
"Act 2 Scene 3: Outside Friar Lawrence's cell",
"Act 2 Scene 4: A street in Verona",
"Act 2 Scene 5: Capulet's mansion",
"Act 2 Scene 6: Friar Lawrence's cell"
]
You can use the hasPrefix(_:) method with the romeoAndJuliet array to count the number of scenes in Act 1 of the play:
romeoAndJuliet 배열에서 Act 1 장면을 세려면 hasPrefix(_:) 메소드를 사용해라.
var act1SceneCount = 0
for scene in romeoAndJuliet {
if scene.hasPrefix("Act 1 ") {
act1SceneCount += 1
}
}
print("There are \(act1SceneCount) scenes in Act 1")
// Prints "There are 5 scenes in Act 1"
Similarly, use the hasSuffix(_:) method to count the number of scenes that take place in or around Capulet’s mansion and Friar Lawrence’s cell:
접미사 hasSuffix(_:)
var mansionCount = 0
var cellCount = 0
for scene in romeoAndJuliet {
if scene.hasSuffix("Capulet's mansion") {
mansionCount += 1
} else if scene.hasSuffix("Friar Lawrence's cell") {
cellCount += 1
}
}
print("\(mansionCount) mansion scenes; \(cellCount) cell scenes")
// Prints "6 mansion scenes; 2 cell scenes"
NOTE
The hasPrefix(_:) and hasSuffix(_:) methods perform a character-by-character canonical equivalence comparison between the extended grapheme clusters in each string, as described in String and Character Equality.
Unicode Representations of Strings
When a Unicode string is written to a text file or some other storage, the Unicode scalars in that string are encoded in one of several Unicode-defined encoding forms. Each form encodes the string in small chunks known as code units. These include the UTF-8 encoding form (which encodes a string as 8-bit code units), the UTF-16 encoding form (which encodes a string as 16-bit code units), and the UTF-32 encoding form (which encodes a string as 32-bit code units).
Swift provides several different ways to access Unicode representations of strings. You can iterate over the string with a for-in statement, to access its individual Character values as Unicode extended grapheme clusters. This process is described in Working with Characters.
Alternatively, access a String value in one of three other Unicode-compliant representations:
- A collection of UTF-8 code units (accessed with the string’s utf8 property)
- A collection of UTF-16 code units (accessed with the string’s utf16 property)
- A collection of 21-bit Unicode scalar values, equivalent to the string’s UTF-32 encoding form (accessed with the string’s unicodeScalars property)
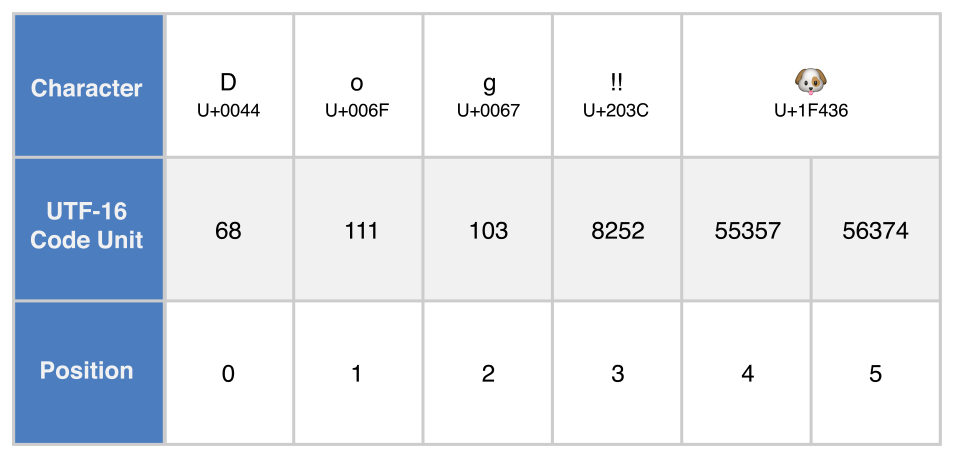
Each example below shows a different representation of the following string, which is made up of the characters D, o, g, ‼ (DOUBLE EXCLAMATION MARK, or Unicode scalar U+203C), and the 🐶 character (DOG FACE, or Unicode scalar U+1F436):
- let dogString = "Dog‼🐶"
UTF-8 Representation
You can access a UTF-8 representation of a String by iterating over its utf8 property. This property is of type String.UTF8View, which is a collection of unsigned 8-bit (UInt8) values, one for each byte in the string’s UTF-8 representation:

- for codeUnit in dogString.utf8 {
- print("\(codeUnit) ", terminator: "")
- }
- print("")
- // Prints "68 111 103 226 128 188 240 159 144 182 "
In the example above, the first three decimal codeUnit values (68, 111, 103) represent the characters D, o, and g, whose UTF-8 representation is the same as their ASCII representation. The next three decimal codeUnit values (226, 128, 188) are a three-byte UTF-8 representation of the DOUBLE EXCLAMATION MARK character. The last four codeUnitvalues (240, 159, 144, 182) are a four-byte UTF-8 representation of the DOG FACE character.
UTF-16 Representation
You can access a UTF-16 representation of a String by iterating over its utf16 property. This property is of type String.UTF16View, which is a collection of unsigned 16-bit (UInt16) values, one for each 16-bit code unit in the string’s UTF-16 representation:
- for codeUnit in dogString.utf16 {
- print("\(codeUnit) ", terminator: "")
- }
- print("")
- // Prints "68 111 103 8252 55357 56374 "
Again, the first three codeUnit values (68, 111, 103) represent the characters D, o, and g, whose UTF-16 code units have the same values as in the string’s UTF-8 representation (because these Unicode scalars represent ASCII characters).
The fourth codeUnit value (8252) is a decimal equivalent of the hexadecimal value 203C, which represents the Unicode scalar U+203C for the DOUBLE EXCLAMATION MARK character. This character can be represented as a single code unit in UTF-16.
The fifth and sixth codeUnit values (55357 and 56374) are a UTF-16 surrogate pair representation of the DOG FACE character. These values are a high-surrogate value of U+D83D (decimal value 55357) and a low-surrogate value of U+DC36 (decimal value 56374).
Unicode Scalar Representation
You can access a Unicode scalar representation of a String value by iterating over its unicodeScalars property. This property is of type UnicodeScalarView, which is a collection of values of type UnicodeScalar.
Each UnicodeScalar has a value property that returns the scalar’s 21-bit value, represented within a UInt32 value:

- for scalar in dogString.unicodeScalars {
- print("\(scalar.value) ", terminator: "")
- }
- print("")
- // Prints "68 111 103 8252 128054 "
The value properties for the first three UnicodeScalar values (68, 111, 103) once again represent the characters D, o, and g.
The fourth codeUnit value (8252) is again a decimal equivalent of the hexadecimal value 203C, which represents the Unicode scalar U+203C for the DOUBLE EXCLAMATION MARKcharacter.
The value property of the fifth and final UnicodeScalar, 128054, is a decimal equivalent of the hexadecimal value 1F436, which represents the Unicode scalar U+1F436 for the DOG FACE character.
As an alternative to querying their value properties, each UnicodeScalar value can also be used to construct a new String value, such as with string interpolation:
- for scalar in dogString.unicodeScalars {
- print("\(scalar) ")
- }
- // D
- // o
- // g
- // ‼
- // 🐶
'iOS 초보' 카테고리의 다른 글
| [swift5.1번역] 5.Control Flow (0) | 2019.07.03 |
|---|---|
| [swift5.1번역] 4.Collection Types (0) | 2019.07.01 |
| [swift5.1번역] 2.Basic Operators (0) | 2019.06.21 |
| [swift5.1번역] 1.The Basics (0) | 2019.06.19 |
| NSMutableAttributedString. 8자리 전화번호 링크걸기 (0) | 2019.01.15 |




